Cuando usamos ChatGPT, Gemini u otros modelos de IA, muchas veces pensamos que “leen todo lo que les enviamos”. Pero en realidad no es tan simple: estos modelos funcionan con un límite de tokens y una ventana de contexto. Entender estos conceptos es clave para sacar el máximo provecho y evitar errores o respuestas poco confiables.
🔎 ¿Qué es un token?
Los modelos de IA no leen directamente palabras ni números, sino tokens, que son la unidad mínima de información que pueden procesar. Un token puede ser:
- Una palabra completa
- Parte de una palabra
- Un número
- Un signo de puntuación o un caracter.

📏 ¿Cuántos tokens equivalen a un texto real?
En promedio, 1 token equivale a 4 caracteres o ¾ de una palabra. Algunos ejemplos:
- Un e-mail breve de 75 palabras → 100 tokens
- Una imagen pequeña → 250 tokens
- Constitución Argentina (PDF) → 6.000 tokens
- Ley 20.744 – Régimen de Contrato de Trabajo (PDF) → 14.000 tokens
- RT 54 – Norma Unificada Argentina de Contabilidad (PDF) → 80.000 tokens
Ejemplos de tokens tomados para el modelo Gemini 2.5 Flash.
🪟 ¿Qué es la ventana de contexto?
La ventana de contexto es el límite de tokens que un modelo de IA puede procesar en una conversación. Todo lo que envíes (mensajes, prompts, archivos adjuntos e incluso las respuestas del propio chatbot) se va acumulando en ese contexto.
Cuando se alcanza el límite, la IA puede:
- Ignorar parte de la información
- Perder detalles importantes
- No conectar bien la información del inicio con la del final
Si eso sucede, es probable que la IA responda con “alucinaciones”.
❓ Preguntas frecuentes
📊 ¿De cuántos tokens es la ventana de contexto?
Depende del chatbot que elijamos, si estamos usando la versión gratuita o paga, y a veces del modelo de IA que seleccionemos.
Este cuadro resume los principales límites de tokens según la plataforma, modelo y plan, a la fecha de publicación de este artículo:
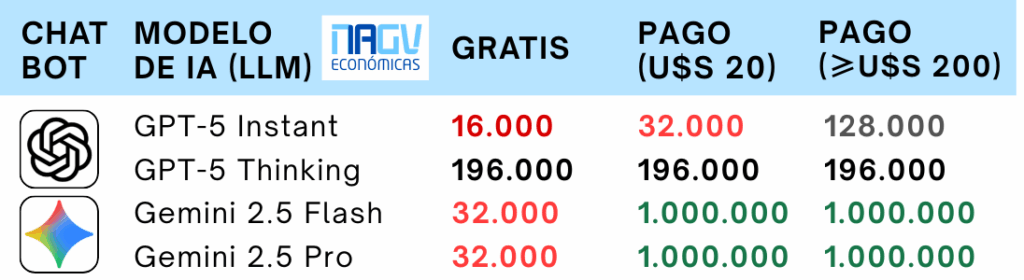
Por eso es clave tener presentes los límites de cada herramienta. Si adjuntás la RT 54 (80.000 tokens) a Gemini en su versión gratuita (32.000 tokens), superarías la ventana de contexto y aumentarías el riesgo de respuestas erróneas o “alucinaciones”. En cambio, con Gemini en suscripción (1.000.000 de tokens), ese mismo archivo entra sin problemas y las respuestas suelen ser mucho más certeras.
En el caso de ChatGPT, al elegir el modelo razonador GPT-5 Thinking (desde el selector de modelos o activando el modo “Piensa más tiempo”), se accede a una ventana de 196.000 tokens. Si no, el modelo base GPT-5 Instant limita la ventana a 16.000 tokens en la versión gratuita y a 32.000 tokens en los planes Plus y Team.
📂 ¿Puedo saber cuántos tokens tiene mi archivo para no excederme?
Sí. Podés ingresar a aistudio.google.com, iniciar sesión con tu cuenta de Google y probar adjuntando archivos o enviando mensajes. La plataforma te mostrará cuántos tokens consume cada acción. Esto no se puede ver directamente en ChatGPT o Gemini, pero sí en AI Studio.
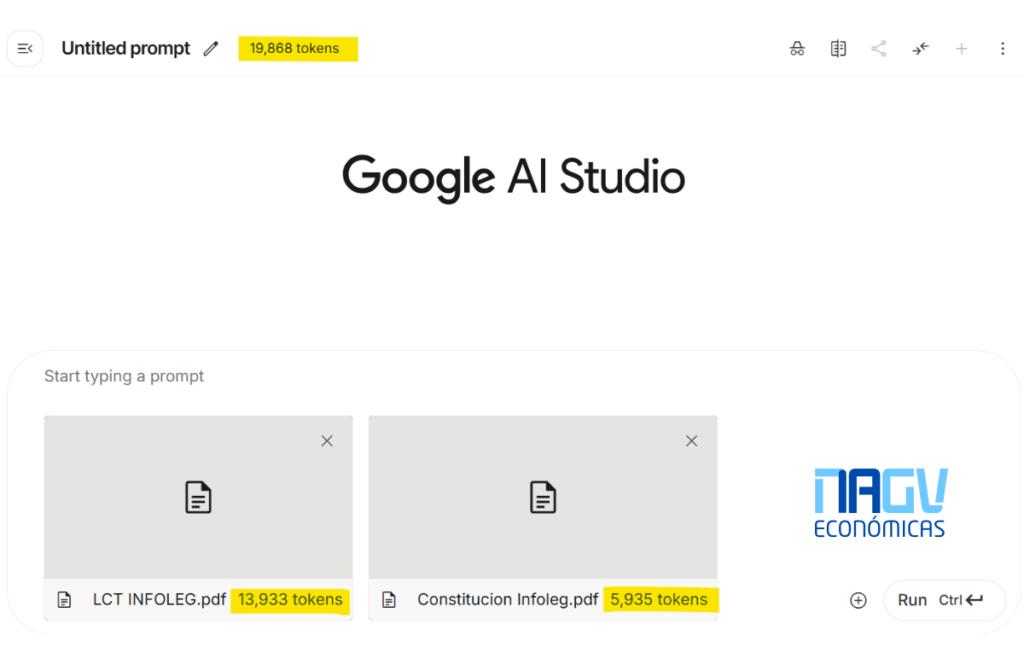
Recomendación: no adjuntar archivos con información privada, ya que Google puede revisar lo que subas a AI Studio, tengas o no un plan de Google Workspace. Aquí no aplica la protección empresarial.
📌 Conclusión
Conocer los límites de tokens y la ventana de contexto es fundamental para evitar alucinaciones y errores de la IA al momento de trabajar con datos precisos. Saber cómo funcionan estos límites te permite planificar mejor qué información enviar y obtener respuestas más confiables.
👉 Para más información como esta, explorá otros artículos en iaeconomicas.com y seguinos en redes sociales para estar al día con todas las novedades: Instagram | YouTube