
Cada vez más, recurrimos a chatbots o aplicaciones con Inteligencia Artificial integrada para resolver tareas de nuestro ámbito profesional: desde algunas más mecánicas como transcribir y clasificar transacciones de documentos contables, hasta otras más complejas como investigar sobre normativas, o analizar estados financieros.
Cuando enviamos un mensaje a chatbots como ChatGPT o Gemini, en realidad estamos interactuando con un modelo de lenguaje grande (LLM, por sus siglas en inglés), que es el verdadero motor detrás de la respuesta. Hoy en día existe una amplia oferta de estos modelos de IA, incluso dentro de un mismo chatbot. Cada LLM difiere del otro en velocidad, costos de procesamiento, memoria y en lo que desarrollaremos en este artículo: su capacidad de resolver problemas. En otras palabras, su inteligencia.
🧠 ¿Cómo se mide la inteligencia de un modelo de IA?
Un benchmark, según IBM, es un conjunto estandarizado de tareas o preguntas que se usan para evaluar el rendimiento de los LLM. Es como un examen que se toma a distintos modelos de IA, en el cual se les presentan problemas específicos (por ejemplo, responder preguntas de ciencias, resolver tareas de programación, entre tantos otros) y luego se evalúa cuántas respuestas fueron correctas. A partir de eso, se asigna un puntaje del 0 al 100%, lo que permite comparar distintos modelos bajo las mismas condiciones. De esta forma, es posible medir qué tan bien se desempeña un LLM en los temas que evalúa ese benchmark. Es decir, cuán “inteligente” es en resolver esos problemas.
Por ejemplo, el benchmark GPQA mide la capacidad de un modelo para responder preguntas de opción múltiple sobre temas científicos complejos, como biología, física o química. Son preguntas que requieren razonamiento profundo y no simplemente repetir definiciones. El test incluye 448 preguntas elaboradas por expertos en ciencias, diseñadas para que no sean fácilmente “googleables”.
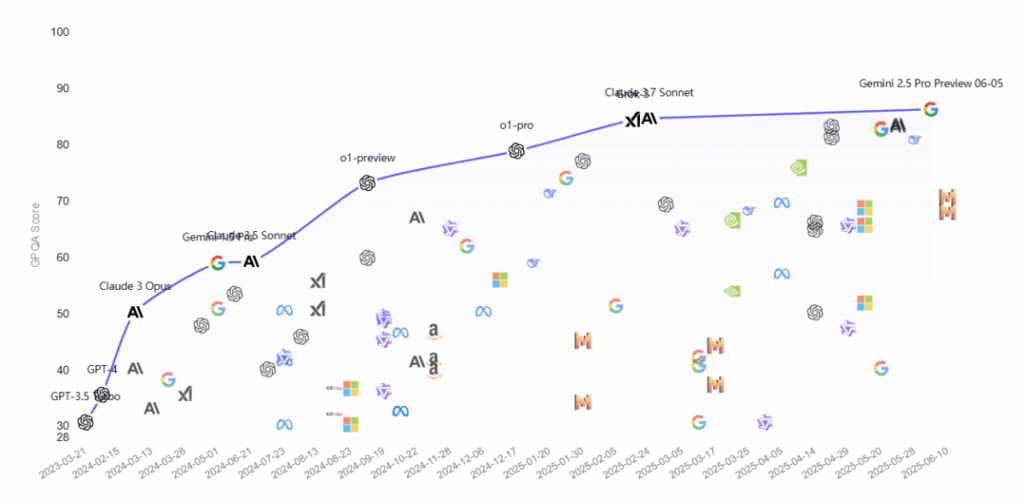
Para tener una referencia, una persona con doctorado (PhD) en estas disciplinas suele obtener un rendimiento aproximado del 65% de aciertos. En marzo de 2023, GPT-3.5 de OpenAI alcanzó un 30% en este benchmark. Solo un año y medio después, el modelo o1 de la misma empresa logró un 73%, superando el rendimiento humano especializado por primera vez en esta evaluación. A la fecha de este artículo, el modelo con mejor desempeño es Gemini 2.5 Pro de Google, que alcanza un 86%.
Este crecimiento muestra claramente la velocidad con la que está evolucionando la inteligencia de los modelos de IA. Sin embargo, así como el GPQA es frecuentemente utilizado como referencia para medir la inteligencia de los modelos, dentro de sus preguntas no hay relacionadas directamente con las Ciencias Económicas, por lo cual deberíamos poner el foco en otras evaluaciones más relacionadas.
📊 ¿Qué benchmarks deberían interesarnos a los profesionales en Ciencias Económicas?
Existe una gran cantidad de benchmarks. Muchos miden habilidades específicas, como HumanEval o LiveCodeBench, que evalúan la capacidad de generar código de programación. Sin embargo, salvo que estemos desarrollando una aplicación o automatización, no son particularmente relevantes para nuestra profesión.
En cambio, deberíamos enfocarnos en aquellas evaluaciones que miden habilidades relacionadas directamente con nuestras competencias. Por ejemplo, existen benchmarks muy utilizados a nivel global que evalúan el rendimiento en matemática, una habilidad clave en Ciencias Económicas. Uno de ellos es AIME 2024, que adapta al formato de evaluación para LLM las 15 preguntas originales del examen AIME de ese año (nivel olimpiada de matemáticas de Estados Unidos). Es interesante observar cómo los mejores modelos con capacidad de razonamiento de grandes jugadores como OpenAI, Grok, DeepSeek y Gemini superan el 89% de precisión, mientras que los modelos sin razonamiento no superan el 52%. Esto puede marcar una diferencia significativa al pedir tareas que incluyan cálculos complejos, como un grossing-up o un análisis financiero más avanzado.
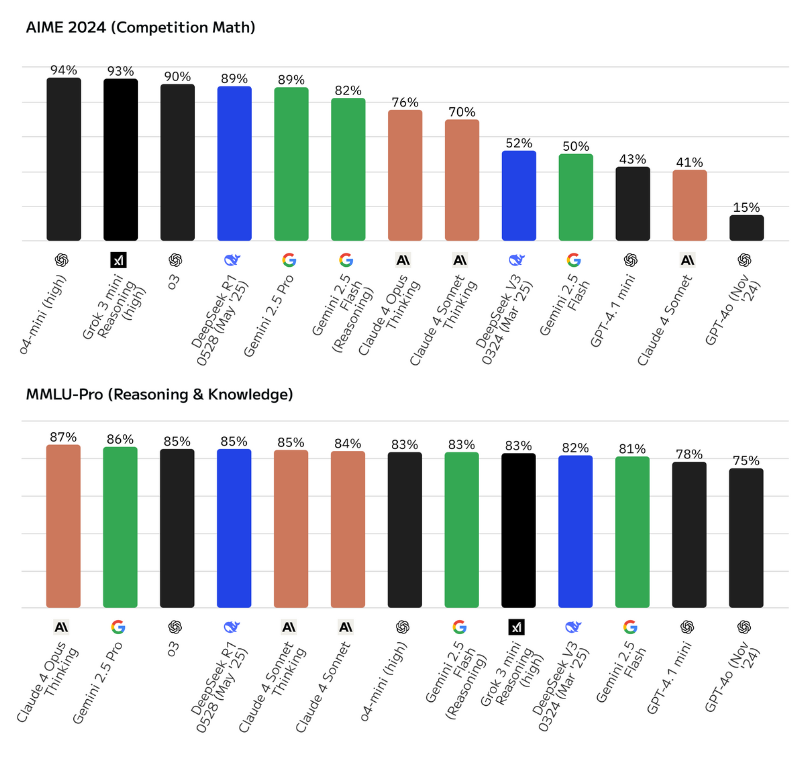
Muchos otros son más abarcativos, e incluyen problemas de áreas como economía, negocios o matemáticas en sus tests, pero estas preguntas representan solo una parte menor del total. Ese es el caso del benchmark MMLU-Pro, que incluye más de 12.000 preguntas de diversas disciplinas. De ese total, aproximadamente el 7% corresponde a economía (econometría, micro y macro), 7% a negocios (administración, marketing, ética), 11% a matemática y 9% a derecho. Es decir, un tercio del total de las preguntas está directa o indirectamente vinculado con las Ciencias Económicas.
Aunque no sea una evaluación totalmente vinculada a nuestros campos de aplicación, pareciera ser una mejor representación que un benchmark como GPQA, el cual no tiene relación directa con nuestras áreas de estudio. En esta evaluación, los modelos de razonamiento de los grandes jugadores obtienen entre 83% y 87%, mientras que los modelos base sacan entre 75% y 82%, no existiendo tanta diferencia como en otras pruebas.
También existen evaluaciones menos conocidas, pero muy relevantes por su enfoque aplicado. La empresa Vals AI desarrolló evaluaciones específicas con tareas propias del ámbito financiero y tributario:
- CorpFin (v2) evalúa la capacidad de los modelos para analizar documentos financieros extensos, como contratos de crédito de 200 a 300 páginas, y responder preguntas que combinan información legal y numérica.
- TaxEval (v2) presenta más de 1.500 preguntas sobre normativa fiscal (principalmente de EE.UU.), evaluando tanto la respuesta como la calidad del razonamiento.
- Finance Agent simula tareas propias de un analista financiero junior, como búsqueda de datos, investigación de mercado y elaboración de proyecciones, a partir de 537 preguntas.
En CorpFin y TaxEval, modelos de IA han alcanzado 71% y 79% de precisión respectivamente, sin grandes diferencias entre modelos con y sin razonamiento. En cambio, en Finance Agent, los resultados caen considerablemente: ningún modelo logró superar el 50 % de precisión al 30/05/2025. Según Vals AI en su web, “los modelos actuales aún no están bien preparados para responder preguntas abiertas del tipo que enfrentan los analistas financieros junior. Tienen dificultades especialmente en el uso de herramientas para buscar información, lo que lleva a respuestas incorrectas. Si bien logran cierto desempeño en tareas simples y repetitivas, fallan casi por completo en las más complejas, como identificar tendencias.”
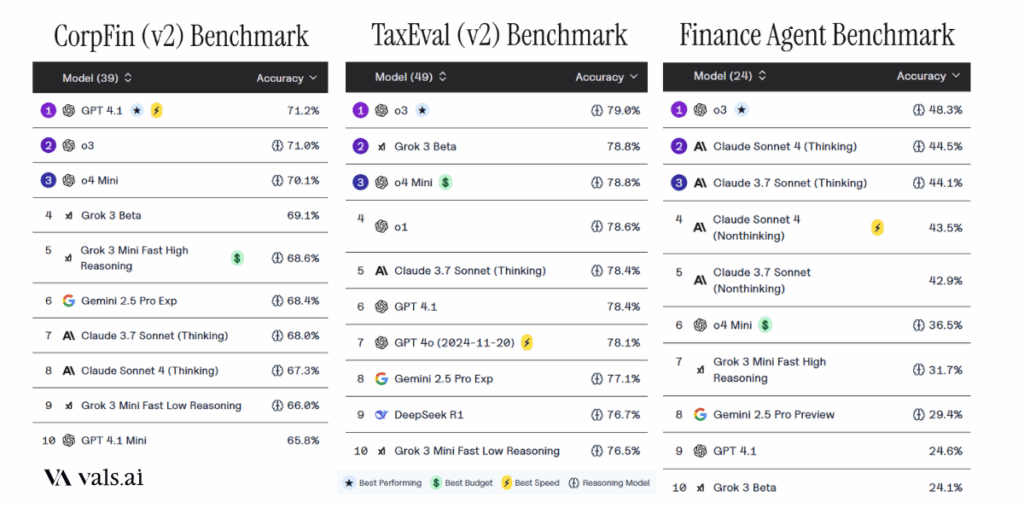
Un dato llamativo es que un modelo más avanzado, como o3 de OpenAI, duplica el rendimiento de uno más limitado como GPT-4.1 (48,3 % vs. 24,6 %), lo que demuestra que los modelos con razonamiento paso a paso logran mejores resultados en estas tareas.
📌 Conclusiones
¿Cuál es la IA más inteligente en Ciencias Económicas? Depende.
Vuelvo a aclarar que aquí estamos considerando solamente inteligencia, es decir, capacidad de resolver problemas. No estamos determinando cual es la mejor o ideal para una tarea, ya que eso también implicaría considerar velocidad de respuesta, costos de procesamiento, contexto, herramientas a las que puede acceder, si es cerrada u open-source, entre tantos otros factores que completarían el análisis.
También debemos aclarar que los benchmarks son muestreos de cómo rinden los modelos en ciertas áreas. Todo dependerá de las preguntas que se incluyan, las formas de evaluar, las instrucciones y otras consideraciones que los desarrolladores de estas evaluaciones tienen en cuenta para cada una de ellas. Que un benchmark indique que un modelo puntúe más que el otro, no significa que, si ustedes intentan resolver una tarea específica, sí o sí la resolverá de mejor manera.
Dicho esto, los modelos con razonamiento llevan la clara delantera en los benchmarks que analizamos, cualquiera sea el modelo elegido, de la empresa que sea. Un claro ejemplo de esto es la prueba que hicimos en IA Económicas: ¿Puede ChatGPT hacer una conciliación bancaria?. En ella vimos como un modelo razonador, o4-mini de ChatGPT, puede resolver una conciliación bancaria corta correctamente, pero no puede hacerlo un modelo base como GPT-4o. Si los comparamos, o4-mini supera a GPT-4o en todos los benchmarks analizados, mostrando la diferencia en inteligencia:
- AIME 2024 (matemáticas): 94% a 15%
- MMLU-Pro (razonamiento y conocimiento): 83% a 75%
- Finance Agent (tareas de analista financiero junior): 36% a 19%
En conclusión, analizando todos los benchmarks revisados hasta la fecha de este artículo, el modelo o3 de OpenAI se perfila como el más inteligente aplicado a tareas propias de las Ciencias Económicas. Sin embargo, Gemini 2.5 Pro, DeepSeek R1 y las versiones con razonamiento de Grok 3 y Claude 4 Opus también muestran un rendimiento destacado y son fuertes contendientes según el tipo de tarea.